Doing what I do for a living, which these days mostly involves creating technology books and courseware, I’m constantly learning new technologies. In a way, my new tech adventures are not much different than the ones most IT pros face, except that mine probably hit more often. Because there’s so much depending on my understanding the new platform or process — and so many other newer platforms and processes waiting for my attention once I’m done with this one — my primary goal is to get in and out as fast as possible.
Trying to organize the layers of complexity and design metaphors inherent in a technology while struggling to figure out if it’ll even do exactly what I want can sometimes be downright intimidating. Without a good plan of attack, I’m dead in the water.
Before I share a couple of the tools that I’ve used successfully in my own learning, it’s worth discussing a real-world (relatively) new technology.
Last April, the operations management monitoring company ScienceLogic conducted a survey of more than a thousand enterprise and IT professionals, seeking their thoughts on cloud adoption. While it’s clear that more and more of the IT workload is shifting to cloud providers (with Amazon Web Services leading the way by every metric), there’s deep and widespread concern over what the impact of the change might be.
31% of respondents felt they lacked the skills to confidently lead a cloud deployment, 50% claimed they lacked the tools to properly manage infrastructure in the cloud, and 28% worried that the shift to the cloud could endanger their current jobs.
Sound familiar? The faster and more disruptive the change, the more we all worry about how — or if — we’ll keep up. And if you think Joe IT Professional stays up nights wondering how he’ll figure it all out, show some sympathy for his manager who’s responsible for dragging an entire department into the cloud.
AWS in particular is on my mind right now because my Manning book “Learn Amazon Web Services in a Month of Lunches” just came out. AWS was a technology I first struggled to understand more than a decade ago when I needed to build my own public-facing web conferencing system (using BigBlueButton). It was a long journey between that first EC2 server and the comfort level and deep experience I reached before attempting the book, but the things I got right — and wrong — while taking those first steps went a long way to shape how I now teach IT topics.
Sequential vs scan-and-run
How you’ll learn a skill partly depends on what you’re planning to learn. If you’re looking for an introduction that will take you from zero to functional on a full-stack, multi-tier environment like AWS, then you might be safer going sequential. Starting at the beginning can help you avoid missing critical details — like the way billing or security work on AWS. Trust me: if you don’t like the idea of surprise four-digit monthly service charges or compromised infrastructure, then you don’t want to skip the billing and security basics.
But if it’s a standalone software package (like a virtualization technology or a new IDE) that you can safely test a few times in your own network before actually deploying for real, then fasterer is gooderer. For this kind of project I will often fire up a clean Linux container using LXC (which, for exploring new software, I find far preferable to Docker) or, when the application I’m working with requires host kernel access (like SELinux), a Linux virtual machine on Virtual Box.
By “scan-and-run” I mean carefully crafting a search string in DuckDuckGo.com (or one of those other search engines whose names escape me at the moment), quickly picking out the information you want from the results, and trying it on your disposable virtual server. Didn’t work? Congrats. You’ve just learned something you didn’t yet know.
Just make sure to properly document both your failures and successes so you don’t have to walk around the same park over and over again.
The command line
Given a choice, I generally prefer working from the Bash command line over GUI consoles. It’s not because I’m a command line snob (although I am), but I find the unambiguous and trackable nature of a CLI works well with iterative experiments. In plain language, that means it’s easier to retrace my steps to figure out exactly what worked and what didn’t. And don’t forget that Bash error messages can easily be recycled into terrific internet searches.
Another CLI advantage: the predictable patterns of a well-designed shell environment can make it even easier to anticipate functionality than a well-designed web GUI. Let me illustrate that using the AWS CLI. Once it’s installed and properly configured, even running `aws` without any arguments will get you something useful. Notice how the output guides you to add `help` to any partially completed command to return contextual assistance.
$ aws
usage: aws [options] <command> <subcommand> [<subcommand> …] [parameters]
To see help text, you can run:
aws help
aws <command> help
aws <command> <subcommand> help
aws: error: too few arguments
It’s true that there’s plenty of help available through the GUI: all AWS console pages have links to extensive documentation resources. But that would be AWS documentation which, while well written and carefully maintained, is usually very, very wordy and sometimes a bit confusing. The inline CLI docs are much more focused and get you in and out more quickly.
Just being familiar with how to access this kind of information can make you much faster and more effective…even through the early learning stages. And the basic structure is available far beyond just AWS.

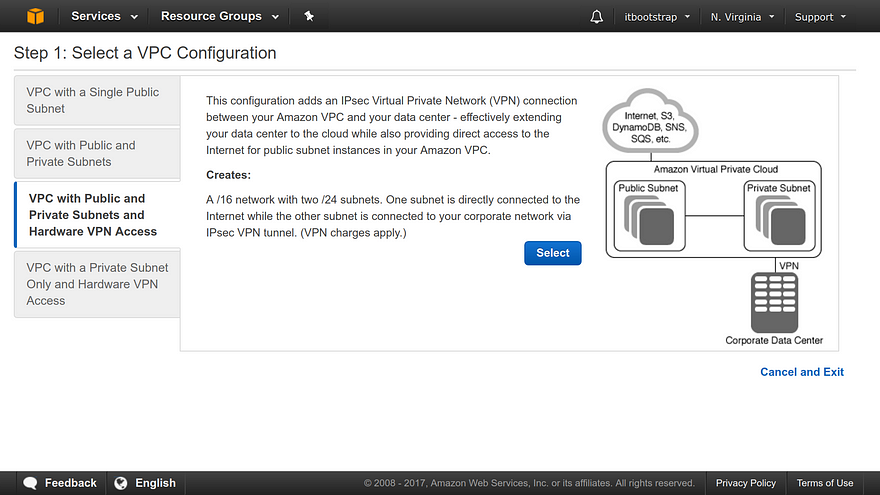
On the other hand, as I wrote in my book, I feel that the AWS browser console is actually a better place to first come to grips with the workings of Amazon’s cloud. That’s because high-level structure plays such a large role in understanding the way the dozens and dozens of AWS services work together, and the website does such a good job visualizing it. But maybe that’s just me.
Do it yourself
More than anything else, your learning will be the most effective if you roll up your sleeves and try it out. Not only should you duplicate the documentation examples, but change the parameters around to see what breaks. And then plan and execute your own projects based on the technologies you’re learning. Applying your knowledge to the real world is critical.